Having moved towards an architecture of microservices, FINN is already leveraging a number of technologies for identifying and dealing with service outages within this architectural style. With each piece of functionality being comprised of a growing number of individual services, specialized tools are required for detection, analysis and mitigation of errors, and we are already using our fair share: Zipkin, Hystrix, Kibana, Grafana and Sensu to name some.
When it comes to metrics and monitoring of time series data, FINN has traditionally employed an infrastructure based on StatsD and Graphite. Recently, however, we opted to switch to Prometheus.

Prometheus, which is heavily inspired by Google’s Borgmon monitoring system, was originally developed by SoundCloud as a reaction to scaling issues experienced with just StatsD and Graphite. Taking into mind Adrian Cockcroft’s rule #4 of monitoring:
Monitoring systems need to be more available and scalable than the systems being monitored
Prometheus stands out as a great choice for us. Not only is it directly supported by Kubernetes, the future container management platform of choice here at FINN, it has been engineered from the ground up to deal with issues of scale and stability. In this new area of monitoring microservices, Graphite seems to be losing ground.
The switch to Prometheus has been rapidly implemented by all our autonomous service teams. Along with monitoring of the “traditional” application metrics like latency and memory usage, special care has also been taken to ensure implementation of adequate monitoring of business metrics.
Business metrics monitoring
The implications of one failing or partly broken service can be hard to evaluate when you are dealing with a large number of services. Since a complex problem now can be broken up into units that are truly independent, all individual parts can continue to work fine separately, while the end result is just not working. Business metrics monitoring is a key tool to successfully discovering and mitigating problems in this world.
Monitoring business metrics means monitoring the core performance indicators associated with the services you provide. These are the primary features of the business which will potentially suffer if any operational or functional part of the system is not performing. Turnbull describes business metrics as
the next layer up from application metrics […] Business metrics might include the number of new users/customers, number of sales, sales by value or location, or anything else that helps measure the state of a business
(from Turnbull, James: The Art of Monitoring).
Other examples of such metrics are orders per second at Amazon, or stream starts per second at Netflix.
My team at FINN, FINN småjobber (FINN småjobber is Norways leading marketplace for matching labor and demand for help with everyday tasks such as cleaning, moving, delivery and handyman work - and more!) has recently finished implementing metrics monitoring with Prometheus. The effort will require some tuning in the weeks to come in order to adjust thresholds for automatic alerts and so forth, but is already looking quite good.
Here I have collected five tips related to metrics monitoring with Prometheus based on our recent experiences, hopefully you may find some of them helpful.
Counters for the win
Counters are great. Unlike gauges, which can spike when you are not looking, counters has no loss of information between samples.
But learn the core rule of thumb when working with them:
The only mathematical operations you can safely directly apply to a counter are rate, irate, increase, and resets. Anything else will cause you problems.
Tip courtesy of Brian Brazil.
Remember recording rules
Once your data are turned into an instant vector (like when aggregating with the sum function), further application of functions requiring range vectors is naturally not possible. However, there are times when you want to continue transforming your queries, and business metrics monitoring is one area where this fast becomes a reality. Say, if the business metric is number_of_purchases, you want to monitor that the total number of purchases is at a healthy level, across all your servers. Assuming counters of type number_of_purchases{server="X"}, a prometheus query for this is
sum(increase(number_of_purchases[10m]))
This yields a meaningful metric to reason about - the total number of new purchases the previous 10 minutes. To alert on deviances in this metric, functions like deriv, delta and holt_winters may be useful, but these all require range vectors. A solution is to record the data using a recording rule.
Recording rules allow for creating new time series from user-configured expressions, and means you can now query on these as if they were just any other metric.
-
Recording rules are otherwise used to precompute computationally expensive expressions and save them as new time series, and are particularly useful when used in monitoring dashboards (which are often refreshed at frequent intervals).
Business metric monitoring tip #1: Use time() to deal with seasonality
Business metrics, like number_of_purchases, are sometimes varying a lot throughout the day, typically correlated with the traffic to your site, and often also showing trends related to day of week or other signs of seasonality. Functions like holt_winters may help in alerting on such metrics, but sometimes this is not adequate, for example when the general volume is just too low.
At such times, the time function may come in handy. time() returns the number of seconds since January 1, 1970, and as such may for example be used to determine the current hour of day:
(time() / (60 * 60)) % 24
With this in hand, expressions can be built to incorporate special handling for chosen periods, for example to compensate for nighttime hours where traffic is low and when alerts on low volumes typically would be triggered.
Adding the expression + (((time() / (60 * 60)) % 24) < bool 8) * 1000 to a query would for example add 1000 to a metric for hours 00:00 to 08:00, which may then rule these periods out for any alerting thresholds which you may have set.
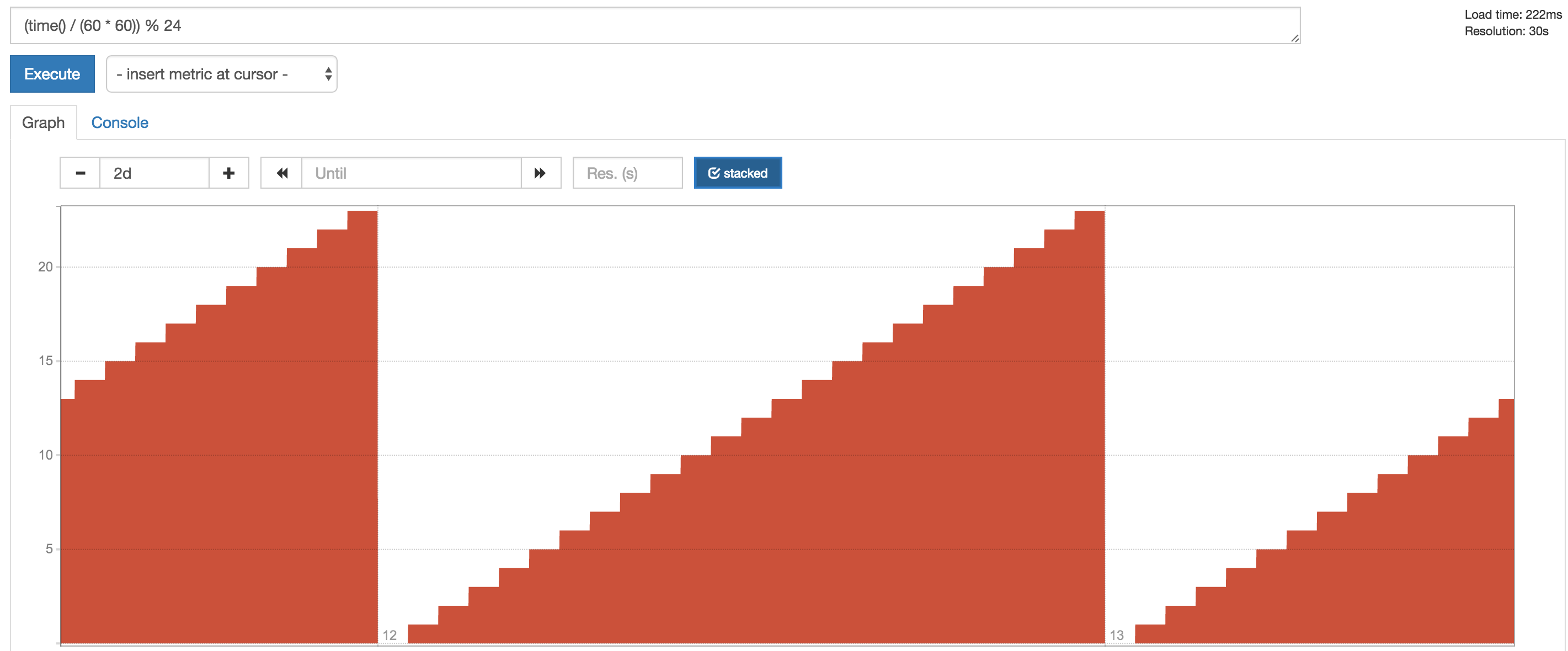
(Depending on your alerting tool, the option to exclude time periods from your alerts may also be configurable in that tool. However, this will usually not remedy the status in any dashboards for the metric, something which using a time()-clause in the query accomplishes).
Business metric monitoring tip #2: Use micro-metrics
Not strictly related to Prometheus as a technology, you may often find that the volume of an interesting metric is so low that efficient monitoring and alerting is hard. Low volumes however, does not mean that monitoring is not useful, it merely means that it will take a longer time to find deviances in the metric in question. The problem is very much analogous to that of doing A/B testing on low-traffic websites (like explained here).
A tip in this situation is to instead, or in addition to your key metrics, monitor correlated micro-metrics (or micro-conversions to use the terminology from A/B-testing).
Here, instead of monitoring the key metric number_of_purchases, one would monitor related metrics like clicks on the “add to cart”-button or the number of product page views. The main point is that the higher the volume, the faster one can detect deviances in metrics. This is fundamentally due to the fact that statistical significance increases with a higher sample population, and a higher sample population is, of course, faster to achieve with high traffic.
Use better graphing tools to effectively tune your queries
Ok, the prometheus GUI comes with some core graphing capabilities, but it really cannot compare to what is provided by a tool like Grafana. In Grafana, which has support for Prometheus out-of-the-box, you can stack metrics, override time intervals, template variables and much, much more, all which enables more efficient testing and analysis of your queries.
Wrapping up, I would like to recommend the previously referenced blog by Brian Brazil at Robust Perception for more interesting Prometheus stuff: http://www.robustperception.io/blog/, and of course the official docs, which also links to where you can get in touch with the community.
Tags: prometheus monitoring metrics